Building an enterprise-level AI module for travel insurance claims is complex. Claims processing requires handling diverse data formats, interpreting detailed information, and applying judgment beyond simple automation.
When developing Lea’s AI claims module, we faced challenges like outdated legacy systems, inconsistent data formats, and evolving fraud tactics. These hurdles demanded not only technical skill but also adaptability and problem-solving.
In this article series, we’ll share the in-depth journey of building Lea’s AI eligibility assessment module: the challenges, key insights, and technical solutions we applied to create an enterprise-ready system for travel insurance claims processing.
Challenge : Complex Challenges of Fraud Detection in Travel Insurance
Key Learnings :
- Adaptive Data Processing Improves Accuracy : Advanced AI validation and clustering manage the complexity of diverse claims data, ensuring that each claim is processed accurately and that fraud detection is precise.
- Real-Time Anomaly Detection Reduces Fraud : Machine learning models detect unusual patterns in claims data, flagging potential fraud in real time, which minimizes manual review and protects data integrity.
- Continuous Model Updating Enhances System Reliability : Daily model retraining keeps the system updated on new data patterns and fraud tactics, allowing it to effectively adapt and identify atypical patterns over time.
In travel insurance, claims data is complex and varies widely by claim type, location, policy, and claimant history. To manage this complexity and ensure accurate processing, a system must adapt to and analyze data at a granular level. Here are the primary challenges our system addresses:
-
High Variability in Claim Data
-
-
- Travel insurance claims combine structured data (e.g., policy numbers, dates) and unstructured data (e.g., scanned receipts, handwritten notes), often with inconsistencies that complicate analysis and validation.
-
Detecting Fraud Amid High Data Volume
-
-
- In high-volume environments like travel insurance, subtle anomalies indicating fraud can be hidden within large datasets. Variability in claims data can obscure patterns that signal potential fraud.
-
Maintaining Real-Time Accuracy
-
- Claims are time-sensitive, requiring real-time validation to support prompt customer service and claim settlements. Data must be validated and analyzed in real time to maintain both speed and accuracy.
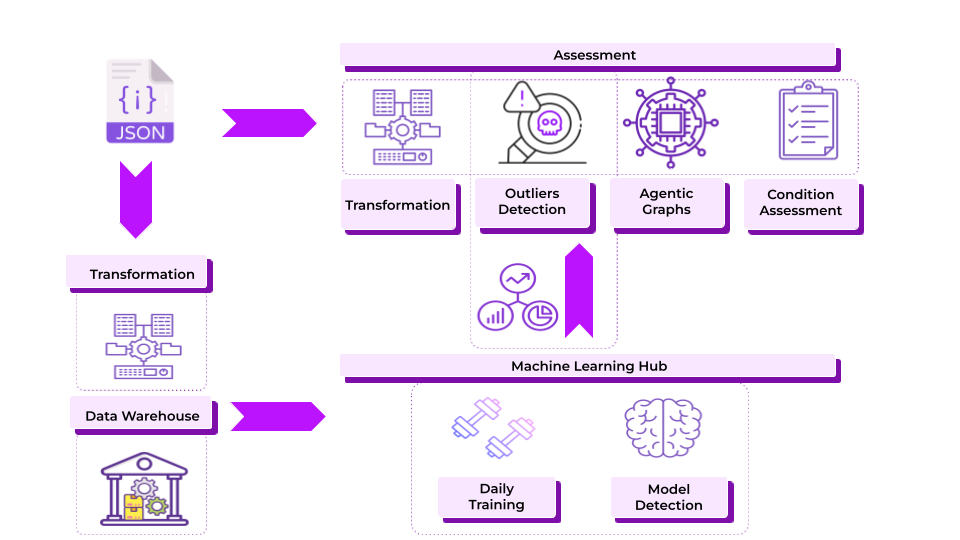
Implementing Advanced Real-Time Validation and Clustering with Machine Learning
To address these challenges, our system integrates Real-Time Validation, Anomaly Detection, and Clustering using machine learning to process claims accurately, flag potential issues, and assess each claim with full context. Here’s how these components work:
Real-Time Validation on Data Ingestion
Real-time validation is the system’s first step, automatically checking each claim against predefined thresholds and rules as it enters the database. This process identifies anomalies before data flows into the processing pipeline, preserving data quality and preventing errors from impacting machine learning models.
- Threshold-Based Validation: The system applies specific thresholds based on historical data and regional averages. For example, a medical claim significantly higher than expected for a certain region triggers a flag.
- Rule-Based Checks: Validation rules detect specific discrepancies, such as conflicting claim dates or unusual patterns.
This step ensures high-quality data flows through the system, supporting accurate anomaly detection and clustering. Validation thresholds and rules are continuously refined to adapt to new claim types and emerging fraud trends, reducing manual interventions, accelerating processing, and supporting timely, accurate responses.
Machine Learning-Powered Anomaly Detection
After validation, claims data undergoes anomaly detection through machine learning models designed to identify patterns or data points that deviate from the typical records, helping detect potential fraud and maintain data integrity. Here’s how it works :
- Regional Pattern Detection: If claims from a particular region suddenly show spikes in specific types, like travel delays or baggage loss, the model flags these patterns for further investigation. This step verifies whether the spike reflects actual events or indicates a larger issue, such as coordinated fraud or errors.
- Historical Pattern Matching for Fraud Detection: The model checks if a claim aligns with known fraud cases, such as repeated high-value claims from the same policyholder within a short period. Flagging these claims helps detect and mitigate fraud before it impacts processing.
This stage preserves data integrity and reduces losses from fraudulent claims by spotting inconsistencies that may go unnoticed during manual reviews. Unsupervised machine learning models, such as Isolation Forests and k-means clustering, are often used in this stage to detect irregular patterns. Additionally, the anomaly detection models are continuously refined, allowing the system to adapt to new patterns and emerging fraud tactics.
Clustering for Similarity Detection and Outlier Identification
Our clustering system analyzes claims data by grouping claims with similar characteristics and identifying outliers, or claims that deviate from typical patterns, known as outliers. The system has three main components:
Variable Mapping, Similarity Grouping, and Real-Time Outlier Detection.
Components of Our Clustering System:
- Variable Mapping: Each claim is processed using 50+ variables that capture a multi-dimensional view of its unique characteristics, such as travel destination, policy type, claimed expense type, and claimant history. Using dimensionality reduction techniques like PCA or t-SNE, these variables are mapped into a 2D projection space, which visually organizes claims based on their similarities, making it easier to identify clusters or outliers.
- Similarity Grouping: Clustering algorithms group claims based on shared characteristics to reveal patterns that may not be apparent through manual analysis.
- Example: Suppose there’s a spike in baggage loss claims from a specific airport. The system groups these claims, uncovering a trend that could indicate an airport-specific issue or coordinated fraud.
- Example 2: Frequent medical claims for similar treatments in a certain country could indicate a potential fraud trend or prompt policy adjustments for that region.
- Real-Time Outlier Detection: New claims are compared against existing clusters to see if they align with known patterns. Claims that don’t fit within any group are flagged as outliers for additional review.
Example: A medical claim from a low-risk region with an unusually high expense may stand alone in the clustering space, signaling a need for further investigation to verify authenticity.
Our clustering model undergoes continuous retraining to adapt to evolving data patterns, new fraud tactics, and shifting travel trends. This ongoing adaptation ensures that the system remains effective over time, identifying new fraud patterns as they emerge.
Dynamic Model Retraining for Continuous Adaptation
The system’s machine learning models undergo daily retraining to stay up-to-date with evolving data patterns and emerging fraud strategies. Each new claim is mapped into the clustering structure, allowing the system to recognize:
- Recurring Claims: If a claimant repeatedly files similar claims (e.g., multiple lost baggage claims in a short period), the model identifies this pattern and flags it for verification.
- Anomalous Claims: A claim that doesn’t fit into any known cluster—signifying it as truly unique or potentially suspicious—is flagged for review.
Continuous retraining ensures the system adapts to changes in claims data, improving the detection of atypical patterns and enhancing fraud prevention.
Our system delivers substantial advantages for travel insurers by leveraging advanced validation, anomaly detection, and clustering:
- Enhanced Fraud Detection: By identifying outliers and spotting anomalous patterns, the system helps insurers reduce fraud, which can lower overall claims costs and improve the integrity of claims data.
- Improved Accuracy and Speed: Real-time validation and clustering enable faster, more accurate claims processing, ensuring that valid claims are handled quickly while anomalies are reviewed promptly.
- Data-Driven Insights for Risk Management: By clustering claims data and identifying trends, insurers gain insights that can inform risk assessments, product offerings, and future pricing strategies.
Through these advanced techniques, our system streamlines claims handling, protects insurers and policyholders, ensures data integrity, detects potential fraud, and enables a proactive approach to claims management.
